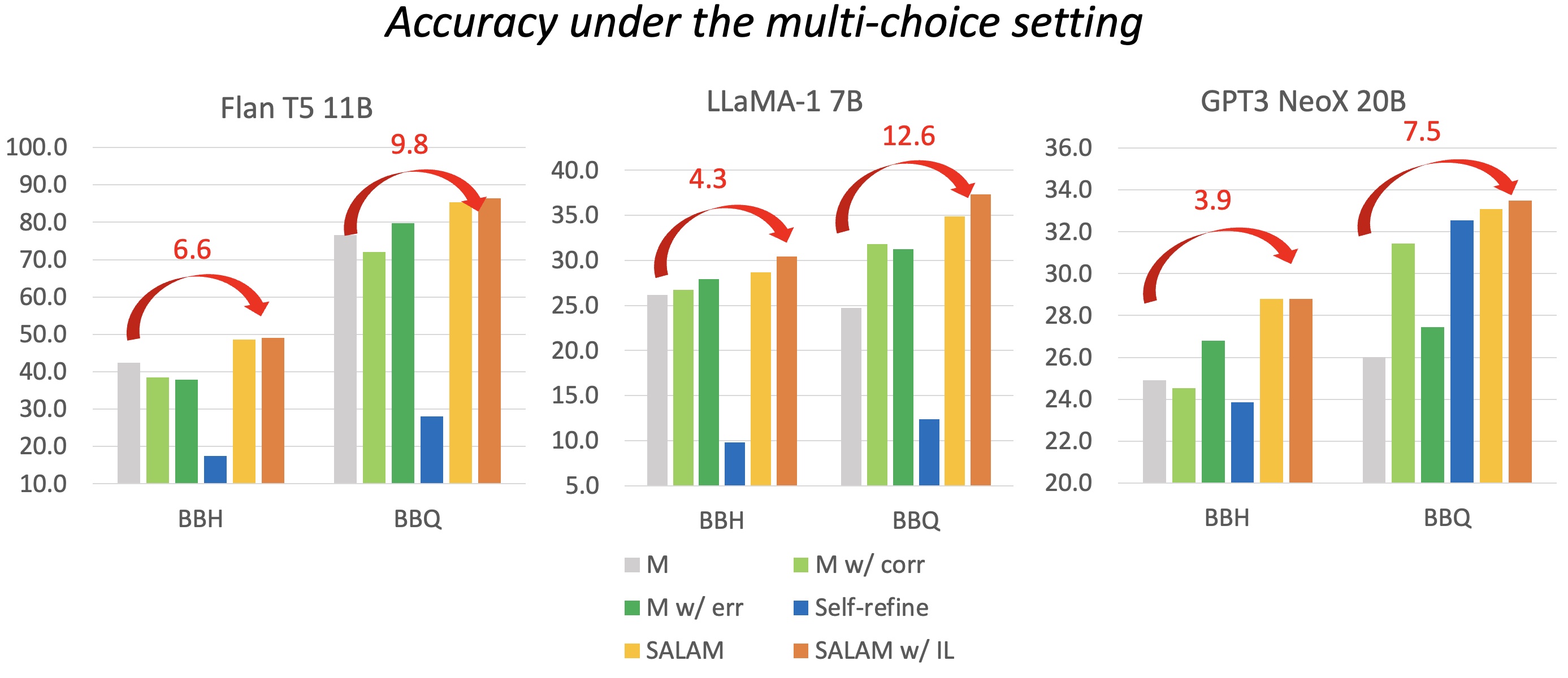
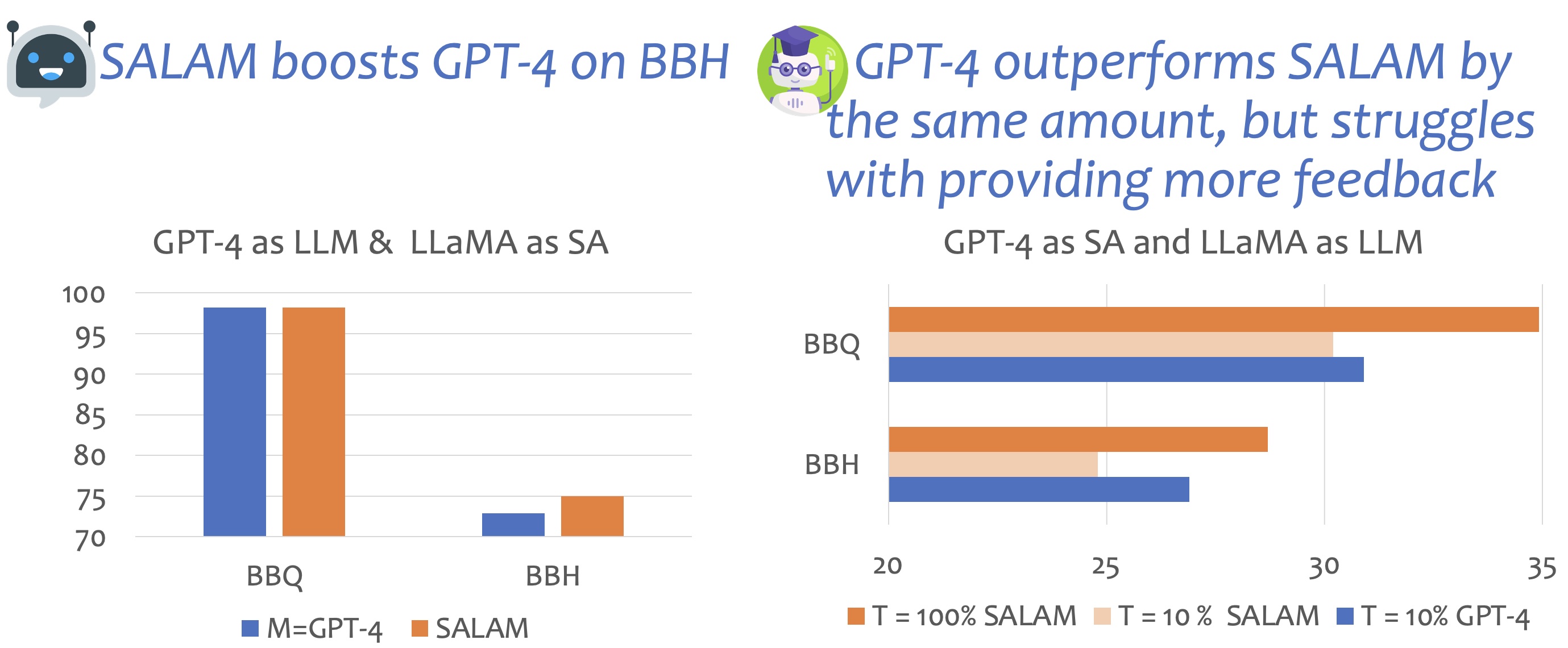
Cooperation Makes LLM Better
😨 LLM may self-reflect, but is the reflection always reliable and reusable?
- Inopportune time to stop or continue the refinement loop
- Too vague feedback to refine response
- Repeated mistakes without knowing previous reflection
🧐 We need an expert to help LLMs reflect
- analyze common misunderstanding and provide global guidelines
- collect the experience for future use
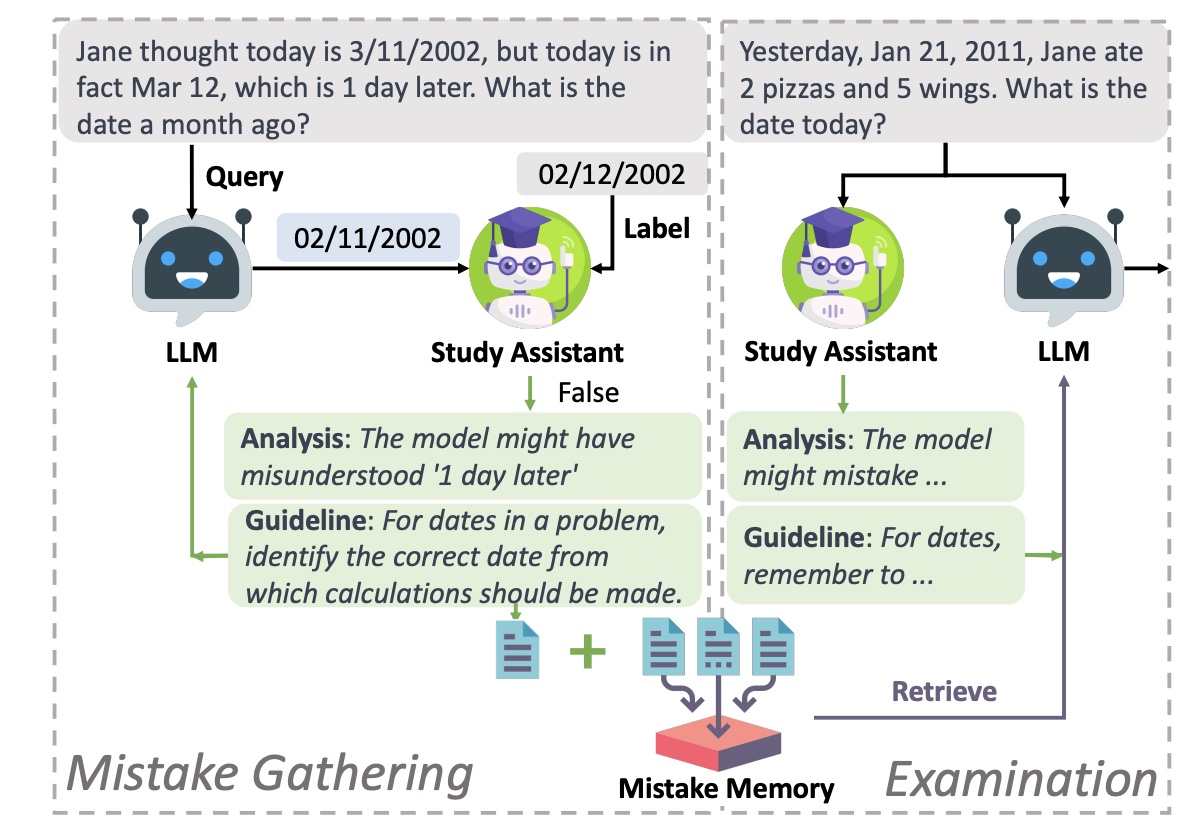
Mistake Gathering & Examination
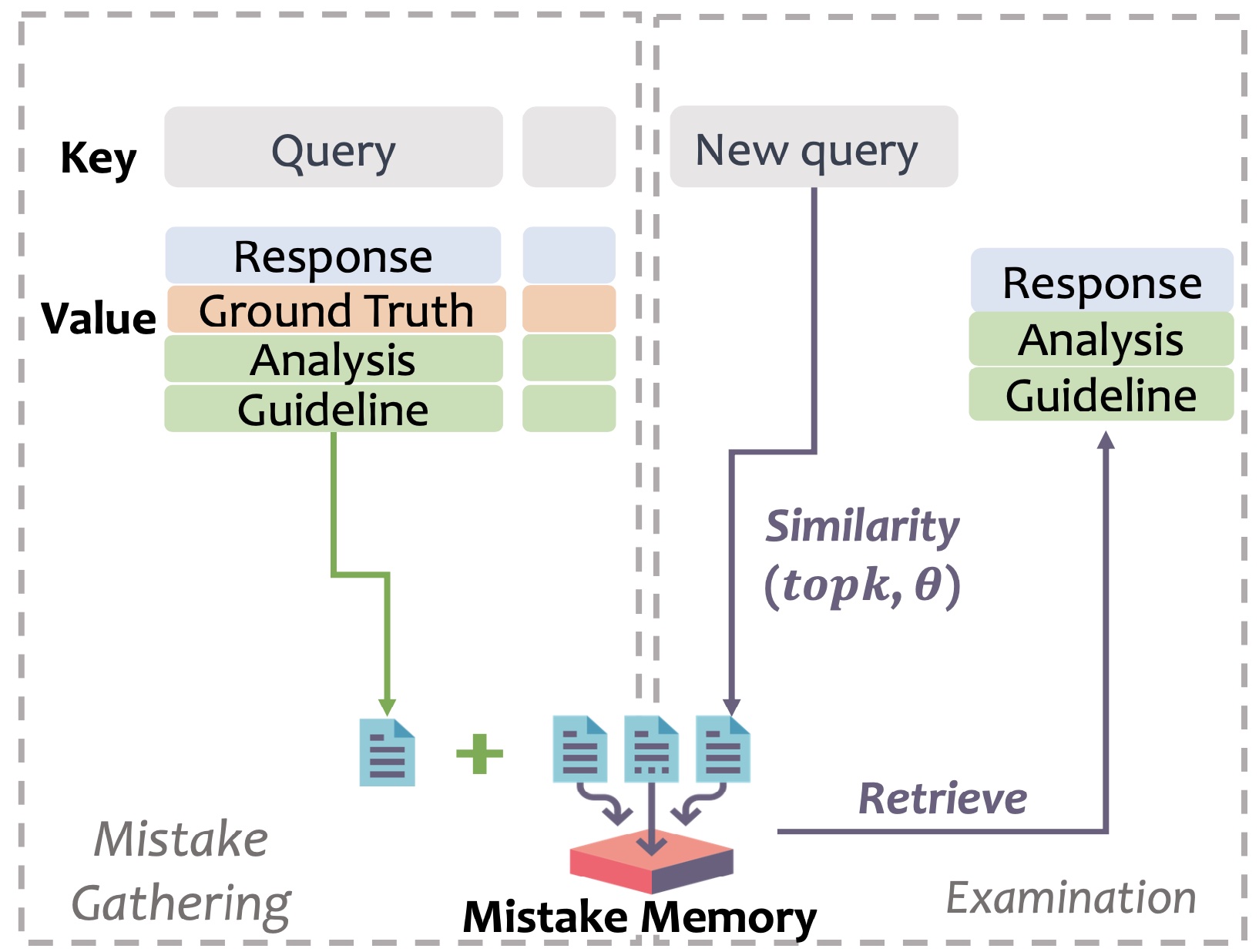
📚 Mistake Memory uiltizes previous mistakes
- Collect mistakes from the training data with ground truth
- Let main LLM interact with the study assistant until it gets the correct answer
- Store these experience into mistake memory
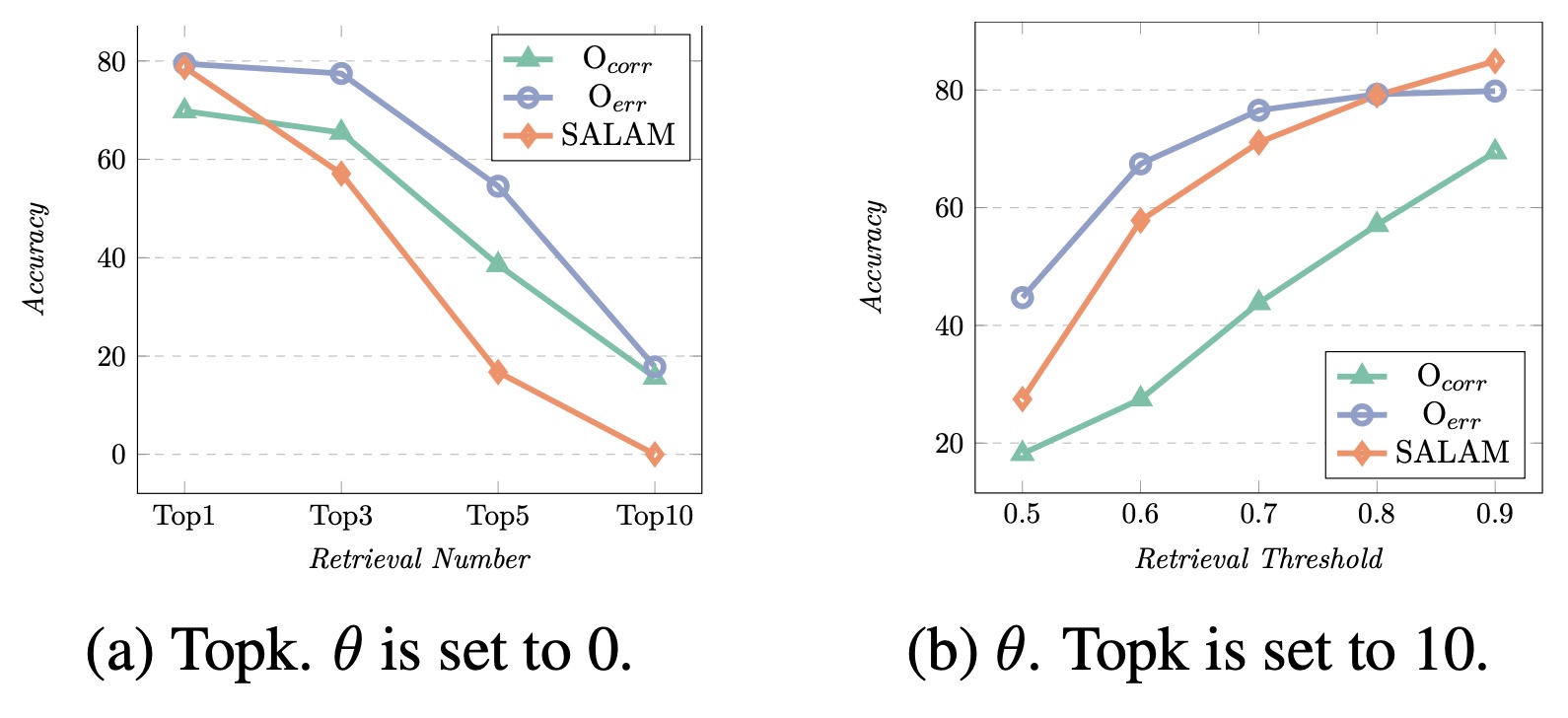
📝 No ground truth is provided during Examination
- Study assistant retrieves similar mistakes from the memory and provides guideline without the ground truth