【CNewSum】具有准确可推断性标注的中文摘要数据集
CNewSum: A Large-scale Chinese News Summarization Dataset with Human-annotated Adequacy and Deducibility Level
Danqing Wang, Jiaze Chen, Xianze Wu, Hao Zhou, Lei Li†
NLPCC 2021
论文:https://link.springer.com/chapter/10.1007/978-3-030-88480-2_31
网页:https://dqwang122.github.io/projects/CNewSum/
引言
为长文本提供一个简明扼要的摘要一直是自然语言处理任务中一个重要的生成任务。在日趋成熟的文本生成技术的帮助之下,自动文本摘要已经可以为人们提供流畅自然短文本概括输入的核心思想。然而,距离摘要技术投入我们日常使用仍然有两大壁垒:(1)高质量中文数据集的缺乏(2)如何使生成的摘要更加接近人书写的风格。
没有足够的数据,AI模型就无法进行学习。目前大部分研究集中在英文,而中英之间的差异也使得英文摘要模型很难直接迁移到中文上,这也就导致了最新的摘要模型和技术难以惠及到我们日常中文环境。
此外,自动摘要模型真正落地到生活中还面临着“无中生有”的挑战。在训练过程中,模型的目标是根据输入的文本,尽量生成和标准答案相似的结果。这里的标准答案一般是由标注人员撰写的摘要。然而人们在进行主旨概括的时候,会不自觉进行一些简单推理或者加入常识。这部分无法直接从输入中获得的知识会导致模型的学习过程变得更加困难,同时也限制了自动摘要模型的性能上限。
为了促进中文摘要的研究,字节跳动团队构建了一个新的高质量中文摘要数据集,并且提供了针对充分性和可推断性的标签帮助研究者更有针对性地提升模型性能。
中文数据集 CNewSum
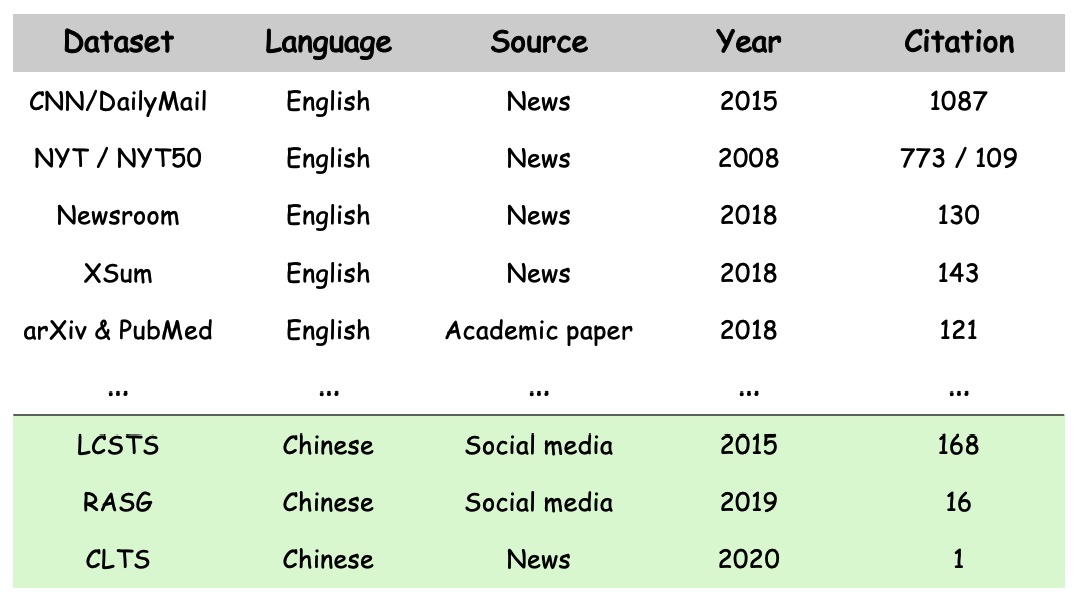
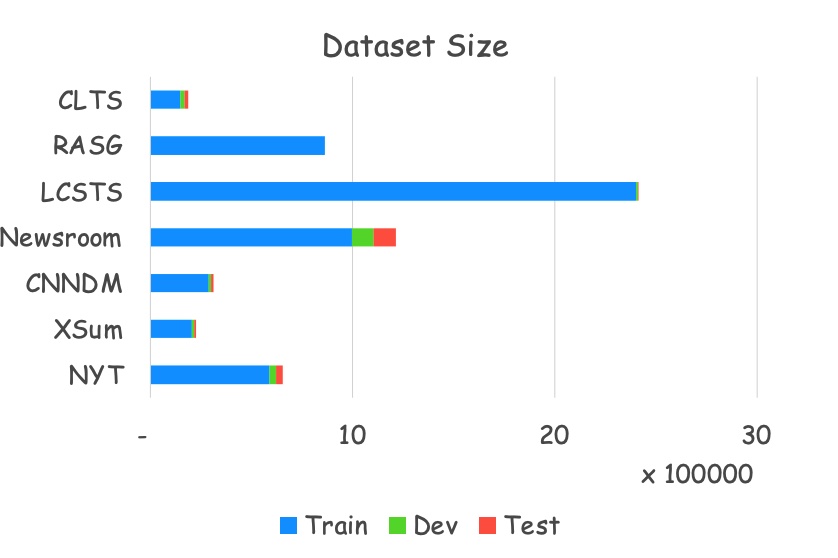
目前大部分摘要研究都集中在英文上,从图1可以看出,最常使用的英文数据集CNN/DailyMail和中文数据集LCSTS都是2015年发表的,但是引用量相差了6倍。此外,其余的英文数据集的引用量也远远高于中文。这一方面是研究者更偏于使用英文,另一方面也需要归咎于目前中文摘要数据集的质量偏低。图2罗列了这些数据集的训练和测试划分,可以发现相较于位于上方的中文数据集,下方的英文数据集都给出了标准训测划分,并且比例相对合理。而中文LCSTS有240万的数据,但是其中测试数据只有700左右。
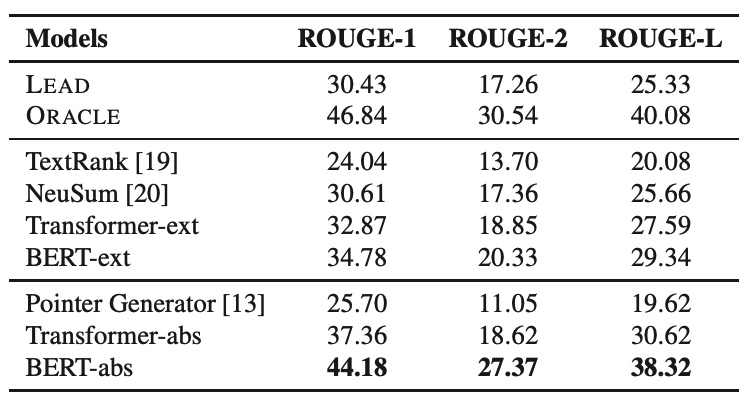
鉴于此,作者率先利用今日头条这个新闻分发平台,收录上千种不同来源的新闻数据,并且由运营团队提供人书写的摘要作为参考答案。除此之外,针对网页数据普遍存在的标点缺失等问题,专门训练标点标注模型进行填充和检查。由此整理出30万的中文摘要数据,并且提供和CNN/DailyMail类似的标准训测划分便于后续研究进行比较。此外文章也提供了常见的摘要模型在该数据集上的性能表现。
充分性(Adequacy)和可推断性(Deducibility)
当我们仔细回顾自己如何进行总结的时候,会发现除了整合文章中出现的信息,我们通常还会进行一些简单的推理,并且补充一下常识。比如一些简单的 单位转化(4000克=4千克),数字加减(300+1500=1800),汇率计算(300美元=1938人民币 等都是为了可读性进行的转化。此外,还会进行一些常识补充,比如 “杭州举办亚运会” 可能会向上概括为 “中国浙江举办亚运会” 等。这类无意识地修改将会体现在人类书写的参考摘要里,却很难被模型隐式学习到,这也就成为限制自动摘要模型性能的原因之一。为了解耦合这部分因素,CNewSum格外提供了两个人类标注:充分性(Adequacy)和可推断性(Deducibility)。
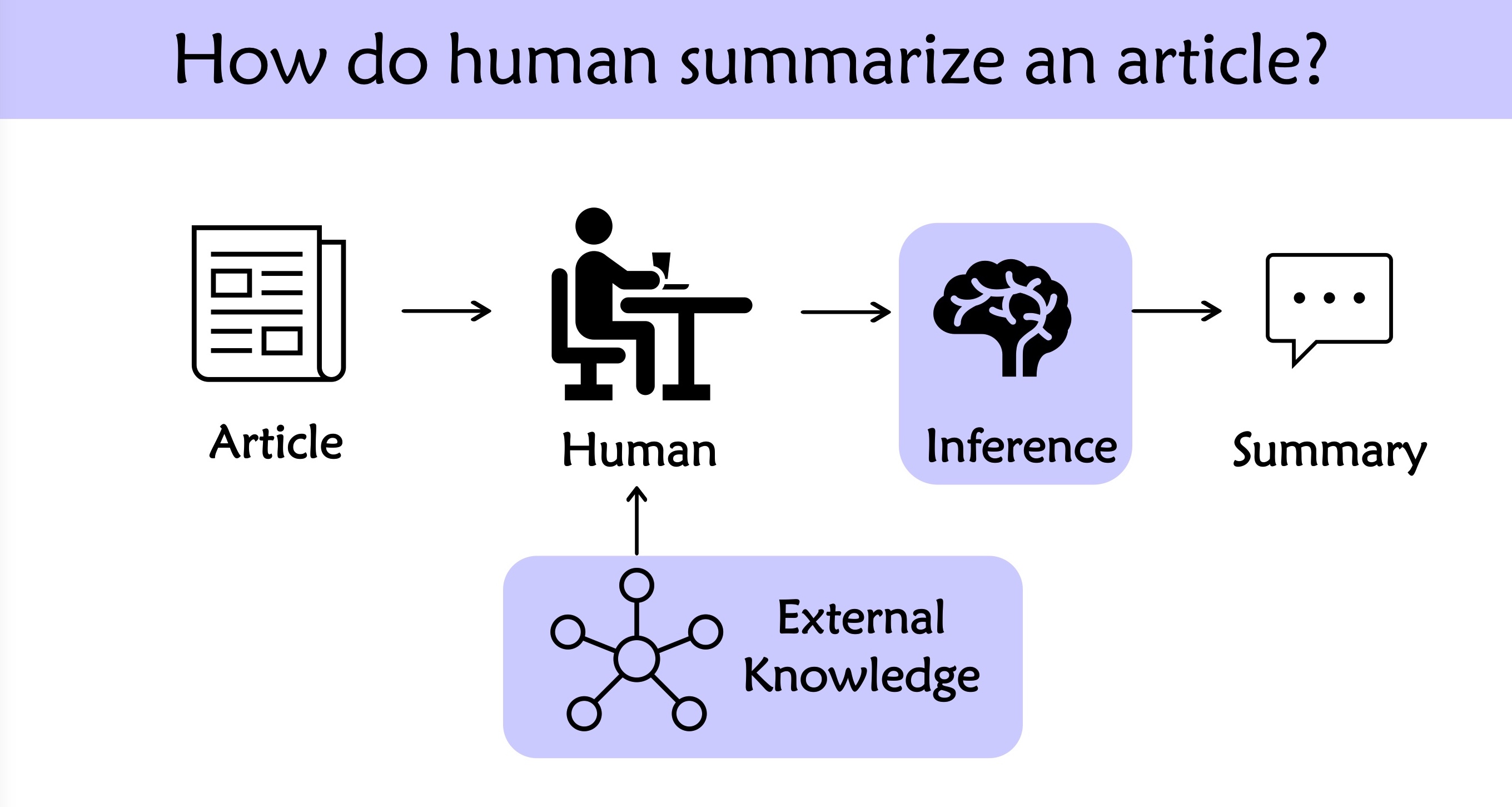
- 充分性 Adequacy:参考摘要中的信息是否都能够直接从原文中找到。当Adequacy=1意味着所有信息都被原文覆盖到,从输入文本到输出摘要的生成过程是独立充分。
- 可推断性 Deducibility:参考摘要中信息是否能够从原文中简单推理得到。当Deducibility=1意味着模型只需要学习一些简单推理,包括前文提到的单位转化、数字加减、汇率计算、名称缩写等。这里的推理基于一些简单的规则,不需要额外的知识。
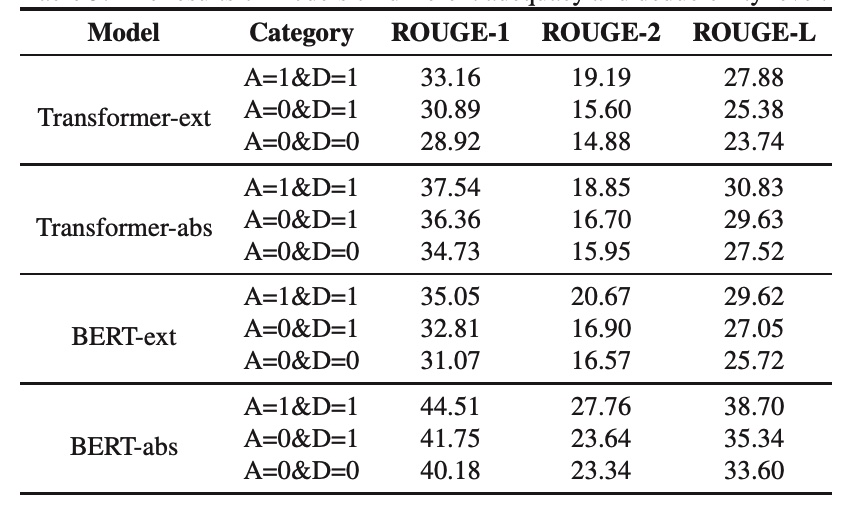
根据以上规则对CNewSum测试集进行标注,可以发现91.08%都满足Adequacy=1&Deducibility=1,这意味着模型可以简单从数据中学习到摘要生成的模式。此外有4.11%数据Adequacy=0&Deducibility=1,意味着这部分需要模型具有一定的推理能力。在这些区间内分别对常见模型进行性能分析可以发现得到图5的结果,证明目前模型可以在较为简单的数据上取得良好的结果,却在需要推理和外部知识的部分留有较大的性能提升空间。
总结
该篇文章提出了一个新的中文摘要数据集CNewSum,包含了30万人类标注的文章-摘要数据,并且额外提供了充分性和可推断性标注。旨在促进中文摘要的发展以及帮助研究者进一步分析当前摘要模型的性能瓶颈。