【HeterSumGraph】异质图神经网络的抽取式摘要模型
Heterogeneous Graph Neural Networks for Extractive Document Summarization (ACL 2020)
Danqing Wang, Pengfei Liu, Yining Zheng, Xipeng Qiu, Xuanjing Huang
论文:https://arxiv.org/abs/2004.12393
代码:https://github.com/dqwang122/HeterSumGraph
知乎:https://zhuanlan.zhihu.com/p/138600416
抽取式摘要的目标是从原文章中选出最为重要的若干个句子,并且将它们重组成摘要。因而,如何构建句子之间的关系,并得到更好的句子表示,就成为抽取式摘要的核心问题。而本文就试图通过引入词结点来扩充句子间的关系,以异构图的方式来建模抽取式摘要,模型被命名为HeterSumGraph (Heterogeneous Summarization Graph)。
建模句间关系
在摘要任务上,建模句间关系的方法可以分成两大类:
- 以RNN(LSTM)为代表的序列模型
- 以Graph为核心结构的模型
序列模型较难捕捉到句子级别的长距离依赖,并且它过于依赖句子上下文的局部信息。相对而言,基于全局信息的图结构更加适合摘要任务。早在2004年,图结构就被用于抽取式摘要任务上:LexRank[1]和TextRank[2]以句子为结点,按照句子之间特征的相似度建边,以无监督迭代的方式对结点进行重要性排序,选出最重要的若干个结点作为摘要。然而,对于以相似度建边的图来说,选择合适的阈值并不容易。近来,一些工作试图通过人工定义的特征来判断句子结点之间是否应该连边(如ADG[3]),或者通过修辞手法或者共同指代等关系来构建图(如RST[4])。还有的试图直接使用全连接图Transformer,让模型自己学习边权。但是这些图都局限于句子这一种结点,没有引入更多的结点信息。
而这篇文章试图通过引入词结点来丰富图结构,更好地建立句子之间的关系。词结点的引入基于以下几方面的考虑:
- 目前的抽取式摘要系统更多依赖于句子的位置信息,句子的内容信息并没有得到很好的编码[5]。甚至在模型输入时,删除句子里面的名词、动词、形容词等等,都对最终结果的影响不大[6]。引入词结点,并且使它们和句子结点反复迭代更新,能够加强词在句子表示中的作用。
- 通过共同出现的词,句子之间的关系得到了扩充。早期依靠相似度建边的图结构,本质也是依赖于句子之间内容的重叠程度。引入词结点后,模型不再需要手动确定相似度的阈值,词和句子之间的包含关系是确定的,而拥有越多相同词的句子间关系越紧密。同时,句子之间的关系不再是单一的连边/不连边,而是根据词的不同有不同的关系。
- 因为词是最小的语义单元,因此它可以作为中介结点链接任何比它大的语义单元。作为句子的中介,它可以更好地建立句子间的关系;作为文章的中介,它同样可以建立多文档关系。因此,模型可以很轻易地从单文档摘要迁移到多文档摘要任务上。
HeterSumGraph(HSG)
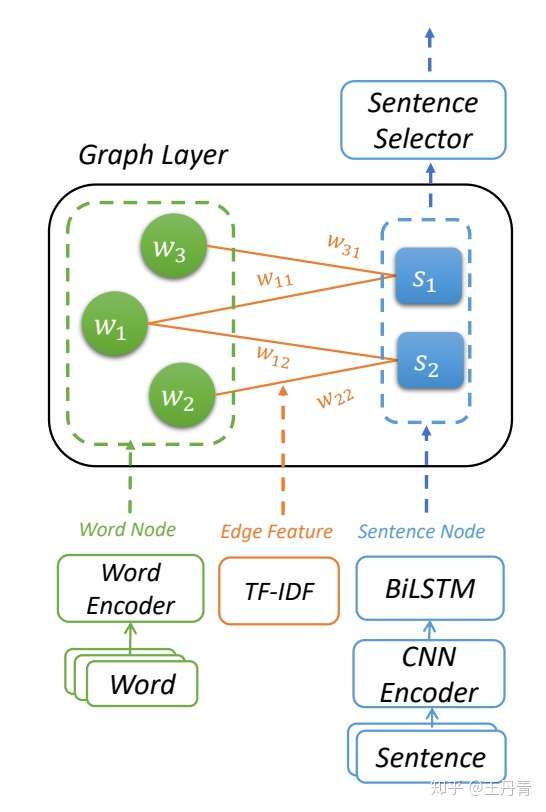
HeterSumGraph的结构如上图1所示,主要由三部分构成:
- 图初始化模块
- 异质图层迭代更新
- 句子选择模块
图初始化模块分别对词结点、句子结点以及词和句子的连边进行初始化,其中句子结点分别使用了CNN和LSTM进行内容和位置信息的编码,而连边选用TF-IDF特征作为权重。
异质图层的更新分成两个方向:词到句子和句子到词。
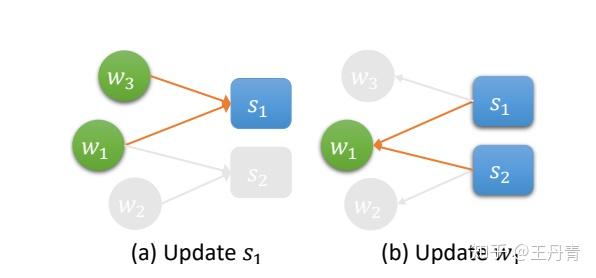
词到句子给了句子结点更好的内容表示,句子到词的更新为词结点提供其出现次数的统计信息,从而使得多次出现的重要词语得到更好的更新。进一步,这个信息将会通过词到句子的再次迭代传递给句子,使得拥有更多重点词语的句子得到更好的表示。这种通过结点度数而得到的频数信息,是图结构区别于基于上下文编码的序列模型的重要特征之一。
句子选择模块主要是对句子进行重要性排序,并且尝试了一些朴素的去冗余操作,如Trigram blocking。
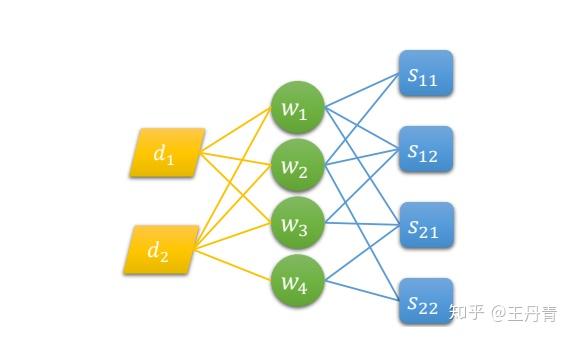
通过添加文章结点,可以从单文档任务迁移到多文档摘要上,如下图所示:
实验与分析
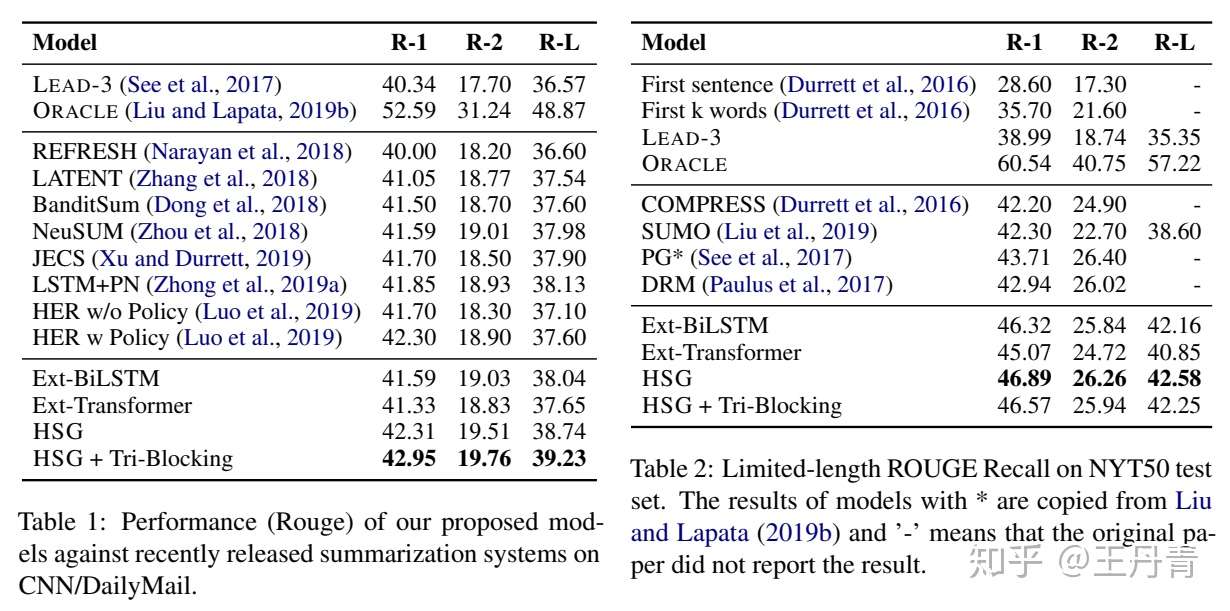
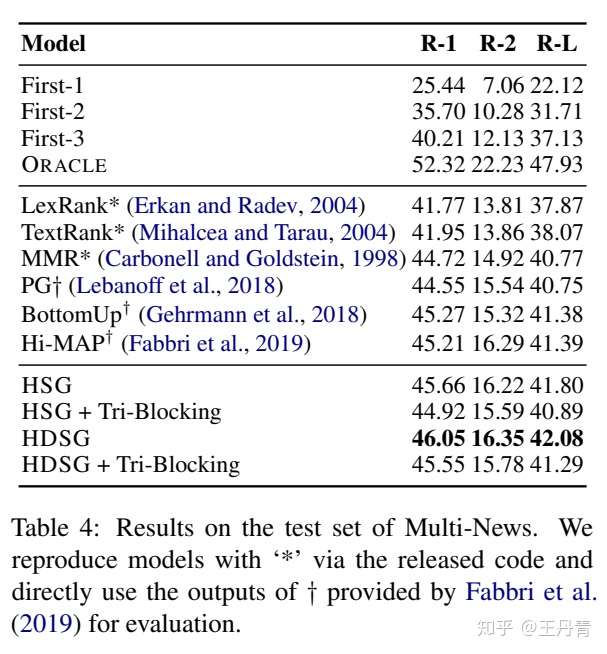
HSG分别在单文档和多文档的三个摘要数据集上进行了测试。单文档摘要选择了较为常见的CNN/DailyMail和NYT50数据集,多文档则选择了ACL2019 Fabbri提出的Multi-News[7]:
那么这种收益是什么带来的呢?除了简单的消融实验之外,文章还进行了进一步探究。作者认为,如果引入词结点以及词语出现频率(即词结点度数)是有帮助的话,那么对于词结点平均度数越高的图,收益越是明显。换言之,如果文章中每个词都只出现过一次,那么得到图结构其实和序列模型差别不大,只有在存在多次出现的词语的文章中,词结点才能够获得多个句子的更新。因此文章按照词结点的平均度数对CNN/DM测试集进行了划分,以折线表示BiLSTM和HSG模型的性能,以柱状图表示两个模型的性能差值:
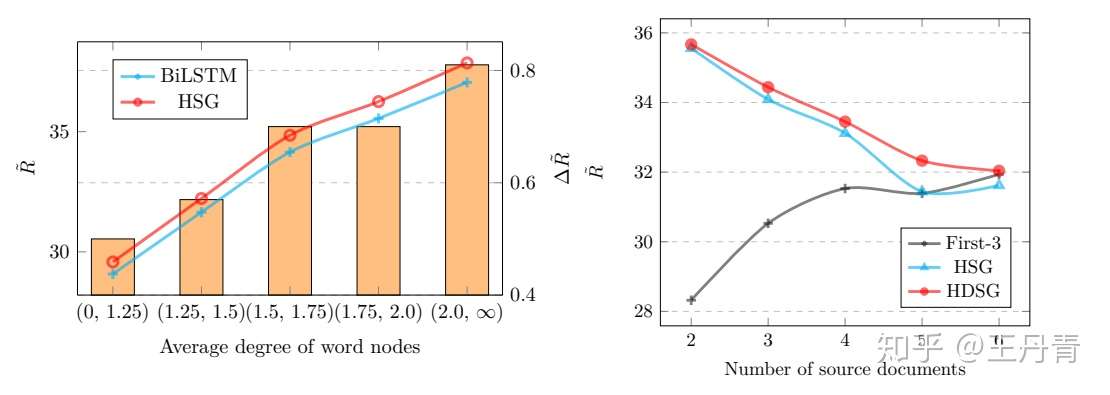
可以看到在词结点平均度数越高的区间上,两个模型的性能差值越明显。因此可以验证,HSG引入词结点带来的优势主要在于多个句子对词结点的更新。
此外,文章还对多文档任务进行了探究。通过对输入文档个数对加/不加文章结点的图模型性能探究,验证了引入文章结点来构建文章之间的关系对多文档摘要是非常重要的,并且随着源文档数目的增加,这个影响更加明显。
引用文献
[1] Erkan, G., & Radev, D. R. (2004). LexRank: Graph-based lexical centrality as salience in text summarization. Journal of Artificial Intelligence Research, 22, 457–479.
[2] Mihalcea, R., & Tarau, P. (2004). TextRank: Bringing Order into Texts, 45(4).
[3] Yasunaga, M., Zhang, R., Meelu, K., Pareek, A., Srinivasan, K., & Radev, D. (2017). Graph-based Neural Multi-Document Summarization. CoNLL.
[4] Xu, J., Gan, Z., Cheng, Y., & Liu, J. (2019). Discourse-Aware Neural Extractive Model for Text Summarization
[5] Zhong, M., Liu, P., Wang, D., Qiu, X., & Huang, X. (2019). Searching for Effective Neural Extractive Summarization: What Works and What’s Next, 1049–1058. ACL
[6] Kedzie, C., Mckeown, K., & Daum, H. (2018). Content Selection in Deep Learning Models of Summarization. In Empirical Methods in Natural Language Processing (EMNLP).
[7] Fabbri, A. R., Li, I., She, T., Li, S., & Radev, D. R. (2019). Multi-News: a Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model. In ACL. Retrieved from http://arxiv.org/abs/1906.0174