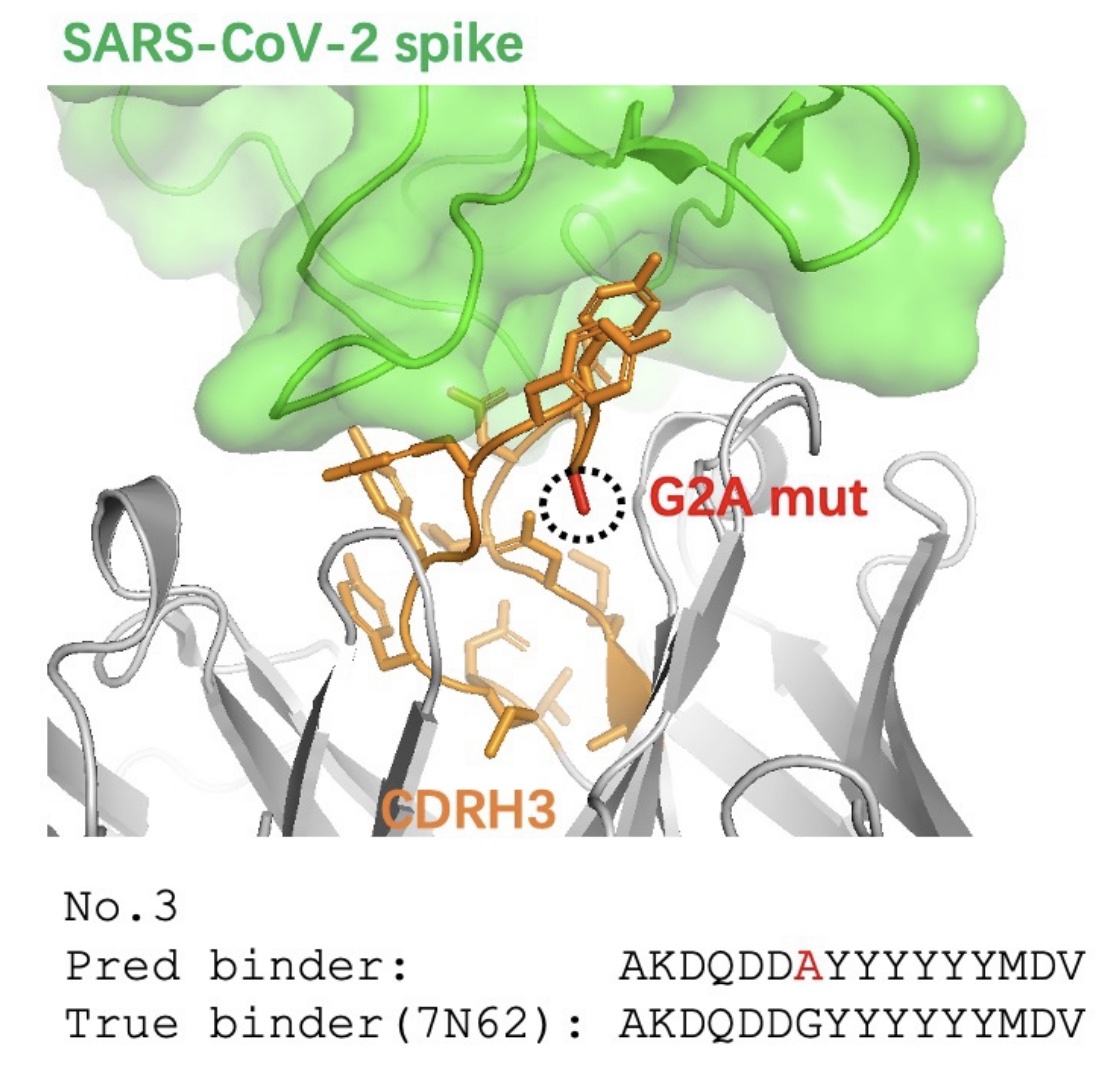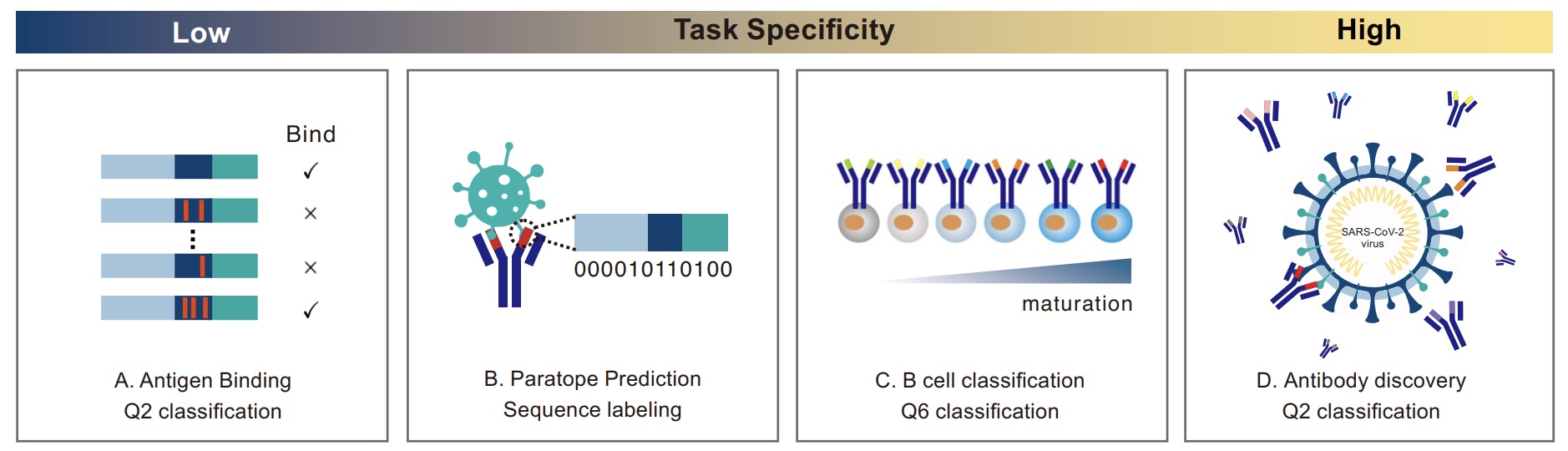
AnTibody Understanding Evaluation (ATUE) benchmark with four antibody prediction tasks. The specificity of tasks ranges from low to high
EvoluTion-aware AnTibody Language Model (EATLM). In Figure (a), AGP randomly unpairs the germline sentence and predicts the ancestor relationship. MPP predicts the mutation position on the germline and the masked mutation residue on the antibody. Based on the input, the three categories in ATUE can be divided into sequence-level and individual-level (Figure b). For individual-level disease diagnostics, we score each sequence in the individual profile and calculate the trimmed mean over all sequences to get the individual score.
Observations: (1) PPLMs perform well on antibody tasks that have a high relationship with structure, but they perform poorly on tasks with high antibody specificity. (2) in most cases, PALMs perform as well as or even better than PPLMs with less pre-training data. (3) PALMs can be improved by incorporating the evolution process, but the evolution information from MSAs does not always benefit antibody tasks.